
Voice-driven web apps using Web Speech API. Reading page content out loud.
The Web Speech API is a browser-based audio interface for processing audio inputs and outputs. We’d like to introduce the feature called Page To Speech for reading content out loud.
Page To Speech allows you to process page content and read it out loud for the user.
Major challenges
- Converting page content to human-understandable text. While reading a simple text generally works fine then reading the web page isn’t an easy task because what you see must be converted to text that when read out loud should match what you see. Example: a list of bullet points where the list content should also be announced as the list of items or processing forms. So, traversing the HTML and providing ready-to-speak text will be the challenge. We’ll use SiteLint’s html-to-speech public package to process the HTML page. We’d like to convert the page content in the closest possible way as the screen reader reads it.
- Process the voice naming details in order to make it more human-readable and understandable.
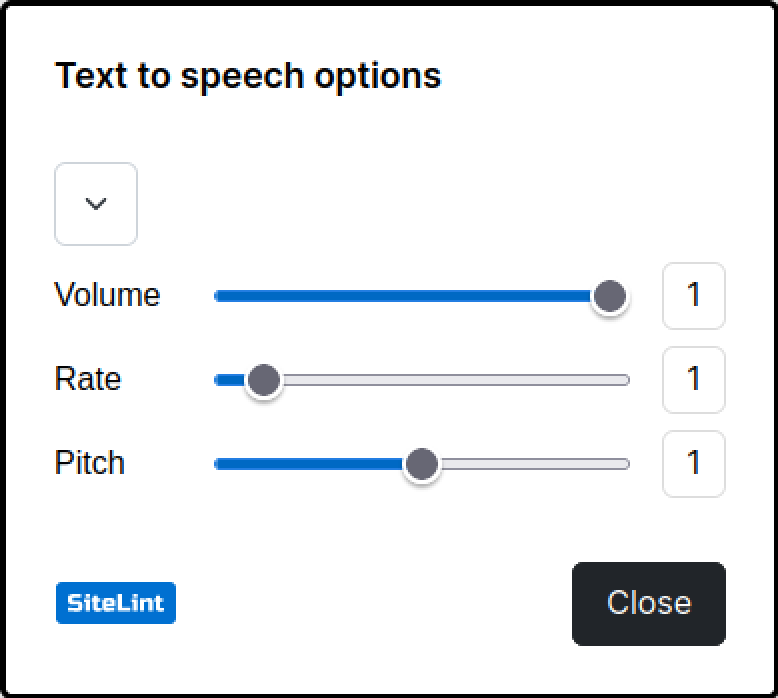
- Provide options to control volume, rate, and pitch.
Benefits
Reading the page content out loud will:
- Increase digital accessibility.
- Allow users to use the feature e.g. while driving a car, to read the page content.
- Text-to-Speech makes it easier for everyone to access web material on desktop, tablet, or mobile devices, enhances citizen engagement, and strengthens corporate social responsibility by providing information in both textual and audio formats.
Let us share a bit more details about Web Speech API.
What’s Web Speech API?
Web Speech API has two components:
- Speech Recognition is available through the SpeechRecognition interface, which provides the ability to recognise voice context from an audio input (normally via the device’s default speech recognition service) and respond appropriately.
- Speech Synthesis is accessed via the SpeechSynthesis interface, a text-to-speech component that allows programs to read out their text content (normally via the device’s default speech synthesizer).
We’ll be focusing on Speech Synthesis and exploring possibilities of its usage, drawbacks, and challenges.
Limitations and drawbacks
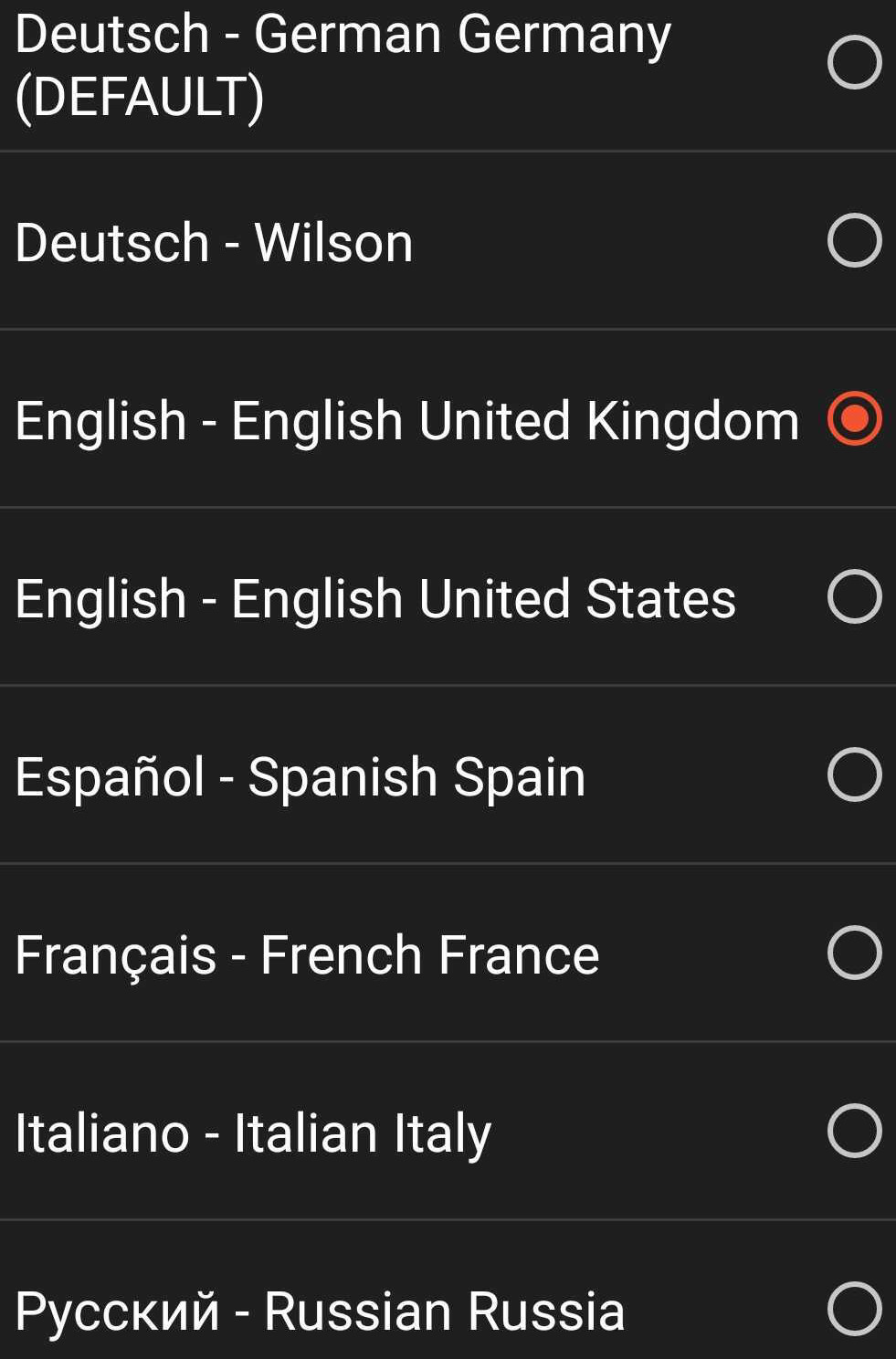
- Inconsistency in the list of SpeechSynthesisVoice data representing all the available voices on the current device. Some browser returns the language of the utterance in the ISO 639-2 code and some (Firefox Focus) in ISO 639-3.
- The voice name is not consistent across browsers. We were trying to make it consistent, but in some cases, it’s not possible or more complex to normalize it. Examples after our modifications:
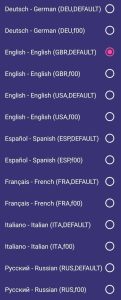
Firefox Focus 107.2.0 (Build #363322328), Android 11 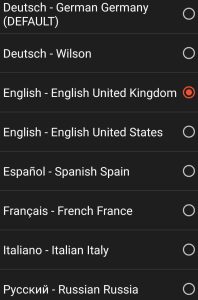
Brave 1.46.138, Chromium 108.0.5359.94, Android 11
- The
voiceschangedevent in some browsers isn’t supported through the methodaddEventListener()so we need to first use propertyonvoiceschanged. - The
boundaryevent returns incosistent value ofelapsedTimein milliseconds (Chrome returns SpeechSynthesisEvent.elapsedTime in milliseconds, not seconds) instead of seconds as specification says. - On Android 11, in the Brave browser (1.46.138, Chromium 108.0.5359.94) the event
boundaryis not called at all. - Firefox 106.0 on Ubuntu 22.10 64-bit provides an empty list of available languages even though Web Speech API is supported.
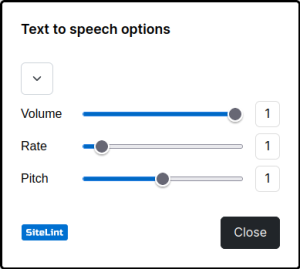
Firefox 106.0, Ubuntu 22.10 64-bit
Browser compatibility
- Read more about Web Speech API browser compatibility.
Demo
The pre-relase demo version of Page To Speech is available for the testing and feedback purpose.
Feedback
We’d love to hear your feedback so don’t hesitate to contact us.
Comments